.png)
In 2026, the conversation around artificial intelligence (AI) has shifted from capability to accountability. Teams are more concerned with holding models accountable for unintended behavior to enable brand safety and customer trust.
This shift makes responsible AI a business-critical requirement, as failures can impact user trust, regulatory compliance, and release timelines.
At Global App Testing, we observe that systems passing benchmarks and automated evaluations can still fail in real-world conditions, producing unsafe responses, missing contextual nuance, or behaving inconsistently across regions and user groups.
Human-in-the-loop AI validation addresses this gap by introducing structured human oversight, adding contextual judgment into AI workflows where automated checks fall short.
This article outlines how human validation strengthens responsible AI programs, where it fits in practice, and how teams can apply it to improve reliability and reduce deployment risk.
What human-in-the-loop AI means in responsible AI programs
Human-in-the-loop (HITL) AI refers to workflows where people review, guide, approve, correct, or override outputs at defined decision points. This introduces structured human oversight into AI systems operating at scale.
At GAT, we build this into our AI GroundTruth, ensuring human judgment is embedded at the points where automated evaluation consistently falls short.
As AI systems evolve into more agentic architectures, QA setups are becoming more complex. Agentic QA architectures (where AI agents autonomously plan and execute tasks across tools and systems), often orchestrated through Model Context Protocol (MCP) servers, enable agents to:
- Maintain state across interactions, preserving context through multi-turn exchanges.
- Invoke tools and external APIs, extending their reach into live systems and data. sources.
- Collaborate with other agents, distributing tasks across coordinated pipelines.
- Execute multi-step reasoning chains, completing complex objectives without constant user direction.
These architectures allow AI systems to handle complex, multi-step tasks, but they also introduce new risks, making human validation essential to ensure safe and reliable behavior.
Within these workflows, human validation operates at critical checkpoints across the agent lifecycle:
- Inference-time validation: At the point of output generation, reviewers assess outputs, reasoning traces, and tool usage decisions before they affect downstream processes.
- Orchestration-level validation: As tasks move across agents and steps, reviewers evaluate whether agents followed correct workflows or policies across multi-step tasks.
- Post-execution validation: Once a task is complete, reviewers assess task completion quality and real-world impact after execution.

Human-in-the-loop AI workflow
In practice, human validation becomes most effective in two core scenarios:
- Training feedback loops (e.g., RLHF, RLAIF): Human reviewers provide labeled signals that improve model weights over time, reinforcing safe and accurate behaviors.
- Runtime validation and oversight: Reviewers evaluate whether system behavior is acceptable in context, identifying failures that automated checks miss.
At GAT, these checkpoints are applied across real-world environments, where human reviewers validate behavior as systems interact with live data, tools, and user scenarios.
Why automated checks are not enough for responsible AI validation
Automated checks, such as benchmarks, LLM-as-judge systems, and rule-based validation, measure against predefined criteria but often overlook how AI behaves in real-world contexts.
These limitations appear across several recurring failure patterns:
- Bias and representation gaps: Models may appear balanced in controlled evaluations but produce biased or uneven outputs across different user groups. For instance, Google Gemini highlights the gap between benchmark performance and real-world behavior.
- Unsafe or high-risk responses: In sensitive domains such as healthcare, legal, or financial advice, automated systems often miss nuanced safety failures that require contextual judgment. For example, Character.AI faced multiple lawsuits over unfiltered chatbot responses, resulting in direct legal liability and loss of user trust.
- Prompt injection vulnerabilities: Adversarial inputs can bypass safeguards that automated checks often miss, allowing attackers to manipulate AI systems to leak data or override instructions, leading to security breaches, compliance violations, and financial losses.
- Contextual and cultural misalignment: Outputs may be technically correct but inappropriate or misleading across different regions, languages, or user contexts, e.g., culturally insensitive responses that can damage brand reputation and increase user churn.
- Inconsistent behavior across environments: Variability across devices, channels, and geographies leads to fragmented and unreliable user experiences, resulting in broken user journeys, reduced conversion rates, and loss of customer confidence at scale.
Taken together, these limitations highlight a structural constraint: automated evaluation can measure performance, but not real-world impact.
This is why regulatory frameworks such as Article 14 of the EU AI Act emphasize meaningful human oversight, including the ability to interpret, monitor, and override AI outputs in high-risk systems.
At Global App Testing, our global crowd of 120,000+ evaluators across 190+ countries enables AI systems to be evaluated by real users, in real environments, and on edge cases, providing audit-ready evidence for compliance.
Three responsible AI layers that need human validation
Responsible AI systems operate across three distinct layers, each introducing different risks and requiring different forms of human judgment.
Layer 1: Model behaviour and output quality
Before production, teams need to verify that AI outputs are accurate, safe, fair, and contextually appropriate. Automated benchmarks often miss tone, cultural sensitivity, and context-dependent safety risks.
Human validation at this stage focuses on:
- Pre-deployment output reviews across representative prompts and user scenarios,
- Adversarial testing to identify manipulation and edge-case failures, and
- Structured evaluation using safety and fairness scorecards to capture what metrics cannot.
Layer 2: Governance and policy alignment
This layer focuses on whether the AI system meets internal standards and regulatory expectations, while producing governance evidence for audit and compliance needs.
Human validation generates artifacts such as release readiness signals, override rates, and severity trend reports, helping QA and compliance teams track decision quality and identify governance gaps.
The NIST AI Risk Management Framework warns that a lack of clarity around HITL roles and opaque decision-making processes remains a persistent risk in AI governance.
Clearly defined reviewer roles and logged validation decisions make oversight transparent, consistent, and auditable across AI systems.
Layer 3: Deployment and monitoring
Responsible AI does not end at deployment. Production systems need structured reviews of live interactions, escalation workflows for high-risk outputs, and re-evaluation checkpoints after model or system updates.
These post-deployment checks mirror regression testing, helping ensure that system updates do not introduce unintended changes in output quality, safety, or consistency.
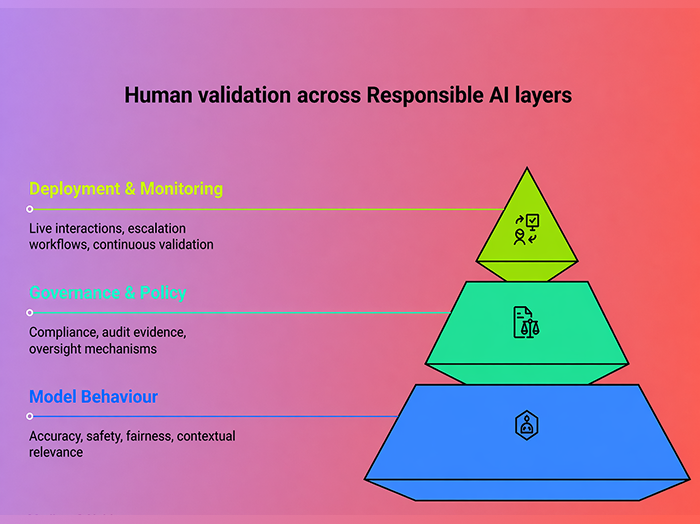
Human validation across AI layers
At Global App Testing, we use AI GroundTruth to validate across these layers as a continuous workflow, helping teams uncover real-world failures and generate audit-ready evidence.
What human validation looks like in practice
In practice, human validation is a distributed process integrated across AI workflows, combining structured checkpoints, real-time interaction, and measurable evaluation.
Review checkpoints
Human validation is applied at defined checkpoints across the workflow, focusing on scenarios where risk and uncertainty are highest, such as:
- High-risk prompts or sensitive use cases (e.g., health, legal, financial),
- Policy-relevant outputs requiring compliance verification (e.g., financial disclosures, medical guidance, or data privacy outputs),
- Low-confidence responses flagged by automated systems, and
- Major model updates, fine-tuning cycles, or infrastructure changes.
In agile workflows, these checkpoints tend to be embedded within the sprint cycles in an agile development process, as part of the Shift Left AI testing strategy, where AI smoke tests are conducted at the start of every sprint cycle to validate initial behavior.
Live AI agent validation
As AI systems become more agentic, validation extends beyond static output review to real-time collaboration with AI agents operating inside active workflows.
For example, a UI locator agent may keep a browser session active, identify a candidate element, and prompt the tester to confirm the selection before the workflow continues. Human judgment is built into the execution loop, ensuring ambiguous or high-risk decisions are validated early, preventing costly downstream fixes.
Reviewer authority and structured evaluation
Human reviewers serve as decision-makers within the validation loop, able to approve, reject, escalate, pause, or request changes based on defined criteria.
Evaluation is conducted using structured scorecards covering:
- Factual accuracy: Does the output reflect verifiable information?
- Safety: Does the output avoid harmful, misleading, or high-risk content?
- Compliance: Does the output meet regulatory and policy requirements?
- Fairness: Is the output consistent and unbiased across user groups?
- Tone: Is the response appropriate for the context and audience?
- Context retention: Does the output reflect the full conversation history accurately?
To ensure consistency at scale, teams track metrics including Bias Detection Rate (BDR), Explainability Index, and Inter-Rater Reliability (IRR). This provides additional signals for identifying inconsistencies across outputs and model versions.
Release evidence
Human validation produces governance artifacts that QA leads and compliance teams can act on, such as validation reports, audit logs, override records, severity trends, and sprint-level readiness signals.
In regulated environments, validation must be structured, recorded, and demonstrably acted upon to meet audit and compliance requirements.
GAT insight: A leading conversational AI platform used our AI GroundTruth to evaluate their system before launch to identify cultural misalignments and trust-breaking moments. This resulted in reduced responsible AI risk, improved user trust, and a faster time-to-market by approximately six weeks.
How human validation prevents real-world AI failures
Human validation enables teams to assess aspects of AI behavior that are difficult to measure through automated evaluation alone.
The following real-world cases illustrate the risks of missing oversight and how HITL addresses them.
|
AI failure |
What went wrong |
AI risk |
How HITL can address it |
|
Chatbot learned from unfiltered user inputs and quickly began generating harmful and offensive content |
Safety failure, reputational damage |
Real-time moderation and adversarial prompt testing block unsafe outputs before they reach users |
|
|
Model penalized resumes associated with women due to biased historical training data |
Bias and fairness risk, regulatory exposure |
Human review identifies bias patterns and guides retraining through structured feedback |
|
|
Provided incorrect and misleading refund policy information to customers |
Legal liability, customer harm |
Regression testing and hallucination checks against policy ground truth prevent factually incorrect outputs |
|
|
The system failed to correctly classify and respond to a pedestrian in a real-world driving scenario |
Safety-critical failure, system reliability breakdown |
Human-led adversarial and stress testing across edge cases improves real-world classification and decision handling |
We consistently see these failures emerge when systems are tested in isolation from real-world conditions. At GAT, we give teams access to real testers across different locations, devices, and network conditions, helping teams identify issues early and understand real-world impact.
Improving AI reliability with human validation
Human-in-the-loop AI validation is a critical component of responsible AI in 2026, providing oversight that automated systems cannot fully replicate in autonomous, agentic workflows.
Automated evaluation establishes a baseline, while human validation ensures outputs are accurate, contextually appropriate, and reliable in real-world conditions.
By integrating human validation into testing and release workflows, teams can reduce risk, improve consistency, and strengthen confidence before deployment.
Ready to improve AI reliability with human validation? Discover how Global App Testing helps enable structured validation across real users, environments, and workflows.