
using%20Sentry%20for%20Alertmanager%20alerts%20header-1.png)
We've been using Prometheus and Alertmanager since 2017. We use it to detect downtime, problems with queues, check if newest release is deployed on production, or if some kubernetes pod is stuck in a restart loop, plus a lot of more.
We are very pleased with this setup. It's easy to configure, easy to understand and Prometheus integrates nicely with other tools. There's also little maintenance overhead. We mainly wanted alerts on Slack where 99% of communication happens, and for some critical alerts, SMS to a person on-call. Alertmanager has also options to configure other receivers.
Our issue with Alertmanager Slack receiver
In 2020, that was almost 2 years ago (!), there was one issue we had with our setup. Occasionally, we'd drown in a volume of generated notifications and we struggled to add hierarchy or simplify to receive only important alerts. We tried to apply grouping and different routing mechanisms and it had improved but still wasn't ideal. It's not entirely Alertmanager's fault. Let's say we've got 3 different alerts:
- number of transactions per minute to inform us about unusual behavior,
- probe failures,
- lack of any activity on background jobs.
They might be triggered at once by broken DNS. Slack you might receive a notification for each one of them, or a group, repeated over and over again (repeat_interval option), without any option to silence them while you work on resolving the problem.
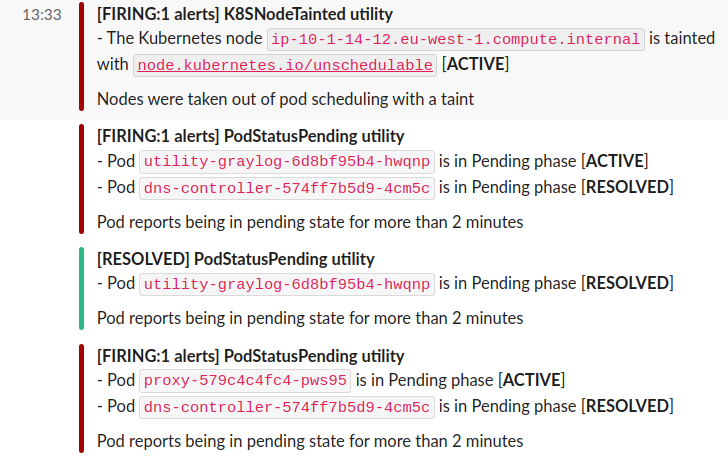
(Example of alerts on Slack from Alertmanager)
Alertmanager is stateless. It only cares about the current state of metrics and what configured alerts match them.
When you configure the alert, you can inspect it in Prometheus web UI:
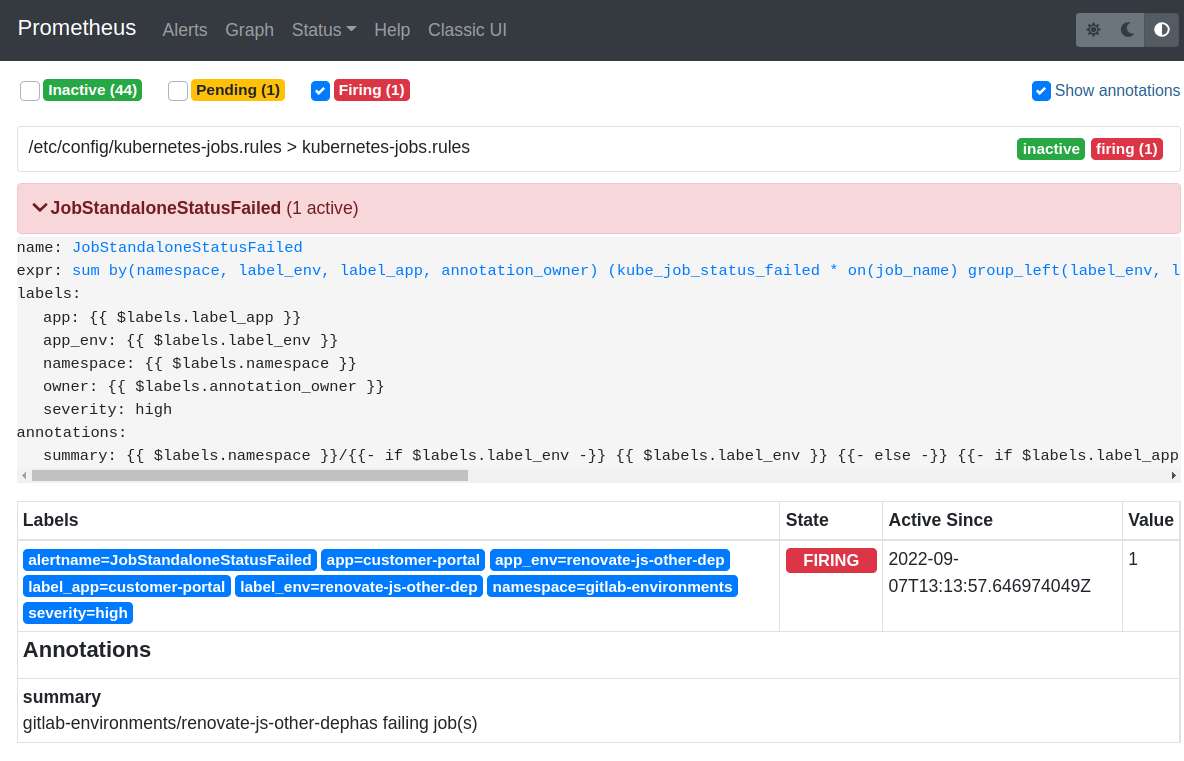
(This is one of many alert we have, in this case it's a notification about failing k8s job in one of review environments)
Alertmanager is stateless. It doesn't keep history of events or notifications. You cannot do any historic analysis based on its state because there isn’t a state to analyze.For that, you have to keep the history somewhere else.
Alertmanager will happily overwhelm the receiver and people on the other side, as soon as the alert's state changes.
Sentry to the rescue
We're fans of Sentry! We use it in every app, we use it to track flaky tests, We also use it to monitor performance of our apps and of end-to-end tests. We already have alerts in Sentry too, but for other things. It has excellent capabilities for issues like grouping and fingerprinting or sampling. You can probably now guess where it's going...
We've added a tiny service into our arsenal of tools. It has few responsibilities, but one of the most important ones is to handle webhooks from Alertmanager and forward them as errors to Sentry.

(Flow of alerts before and after)
Sending alerts to Sentry
This service is written in Elixir, uses minimal resources, and handles any spikes flawlessly. We're far more likely to run into Sentry API limits than have some problems with the service.
On Alertmanager side, we've added a few lines of configuration to add webhook endpoint as a receiver and then routed all alerts to it.
What exactly Alertmanager sends as a webhook is described in the official documentation but handling it looks more of less like this:
For Plug.Router we need to handle POST request.
And then process the params:
What exactly is happening here?
- We process each alert sent by Alertmanager. We've to set set_request_context because we don't want the context of the webhook request inside the reported message.
- Every alert is sent to Sentry via "capture_message"
- For each alert, if its status is resolved, we try to find automatically created issue in Sentry and mark it as resolved automatically. We keep history in Sentry.
build_sentry_call_from_alert/2 is not complex too, it maps incoming alert into something that Sentry would understand, combining various params.
Alerts on Slack via Sentry
We've got our events coming to Sentry. Issues in Sentry are automatically created and resolved too. Now we can set up any kind of Sentry alert we want to. When you do that, make sure to follow their best practices documentation. It will ensure you won't get bombarded on Slack. You'll also not have to be as defensive in Alertmanager queries as you would need to otherwise. Sentry's alerts have more flexibility, like sending notifications only when "The issue is older or newer than..." or "Issue has happened at least {X} times.".
A simple alert may look like this:
If you feel adventurous, you may also consider automatically creating JIRA issues for the team but in that case you're on your own. (Please don't do that.)
Back to Slack notifications... when Sentry sends the alert to Slack, it will look like that:

That's where we usually discuss and triage the issue, or sometimes... ignore it (usually when someone's working on a fix).
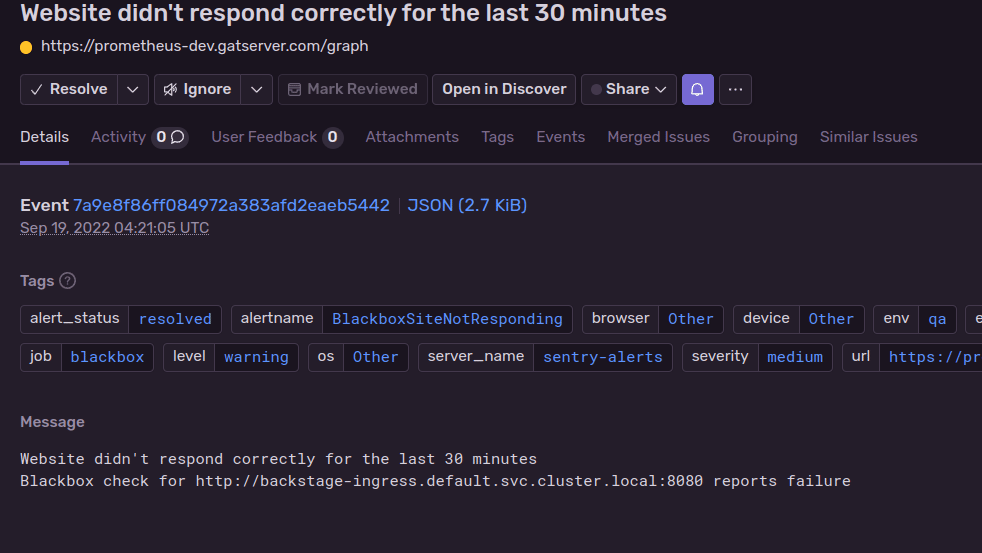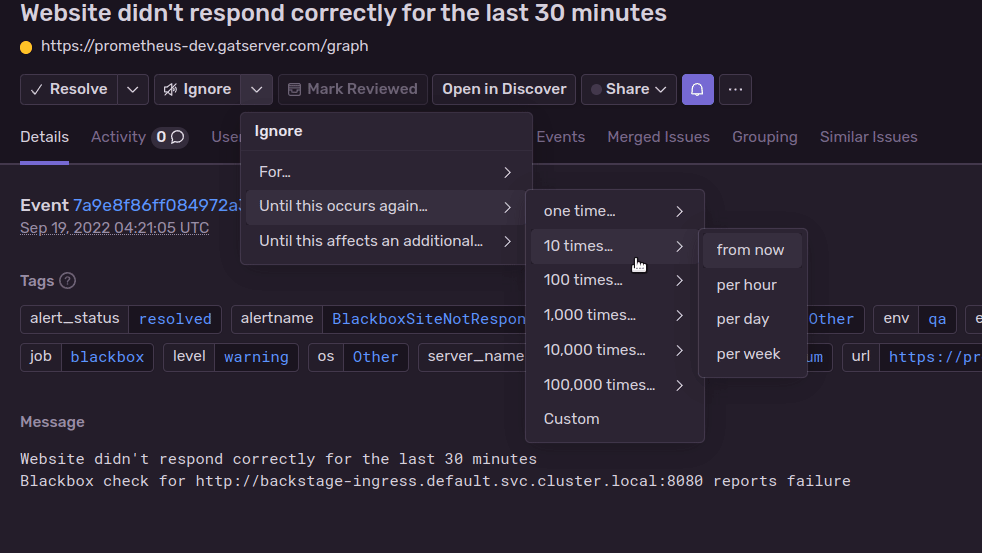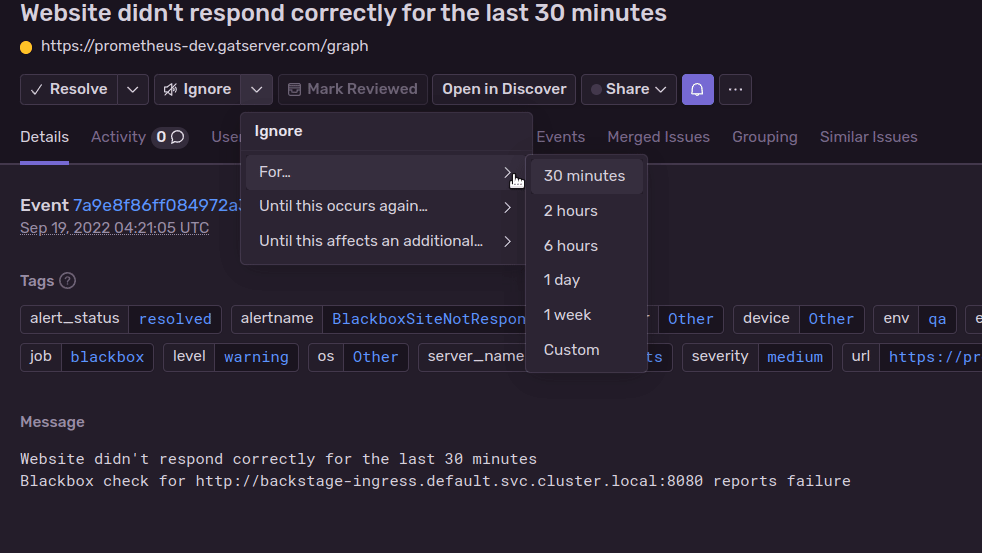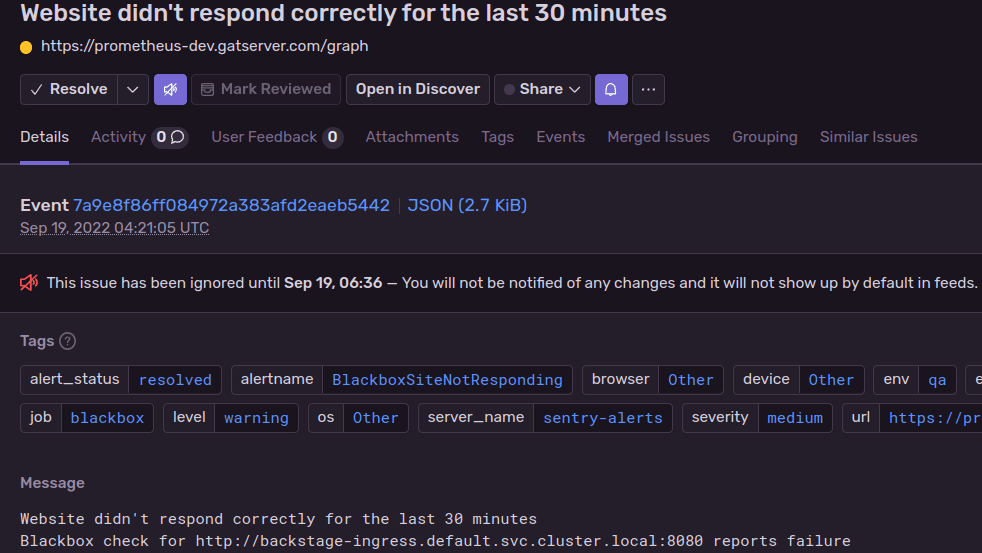
(Demo of ignoring an alert in Sentry)
Conclusion
We've added our service to receive alerts via Sentry in 2020. Alertmanger continues to add new features, and improve so I'm sure some of the features could be moved back to Alertmanager configuration.
In our case, SentryAlerts service is not only forwarding alerts but also automatically assigning some Sentry issues to other people based on tags and doing other Sentry/Alertmanager responsibilities.
In the future, we plan to export Prometheus metrics from our Rails applications and follow the same pattern. If you found this interesting, have a look at our careers page!