

Surprisingly, the most widely known books about DDD do not provide clear practical guidance on how to draw a Context Map collaboratively. This article provides a step-by-step guide on how to draw a Context Map, based on the own experience of the author.
Introduction
Upon delving into Eric Evans' seminal "Blue Book," a revelation struck us: the imperative of crafting a Context Map. This element is the cherry on the cake of Strategic Domain-Driven Design, an endeavor we approached with great anticipation.
As we navigated through the book, the process appeared deceptively straightforward. Chapter 14 lays it out: "Describe the points of contact between the models, outlining explicit translation for any communication and highlighting any sharing." Evans further demystifies the process, asserting, "The Map does not have to be documented in any particular form." This suggests a seemingly simple task: sketch a diagram, adorn it with circles, rectangles, and lines, and voilà, right?
Vaughn Vernon's insights in the "Red Book" also guided our path. He advises, "A Context Map captures the existing terrain." He emphasizes the need for a high-level diagram that succinctly communicates the project's current state, its boundaries, team relationships, integrations, and necessary translations.
In both texts, the authors illustrate their concepts with examples rooted in straightforward domains featuring 2-3 Bounded Contexts. These scenarios seemed clear and manageable.
However, our practical experience told a different story. Implementing these principles into our complex system was far from simple. It demanded seven intensive sessions and considerable asynchronous effort before we reached a point of satisfaction with our Context Map.
Let's take a step back and explore the genesis of our journey.

The Cartographers
The initial challenge we faced was determining the scope of team involvement. Ideally, our team would encompass not just engineers, but also domain experts from diverse areas within our organization, offering a rich tapestry of perspectives and expertise.
However, the practicalities of such an inclusive approach are less than ideal. Broadening the team significantly increases costs and presents a challenge in justifying the resource allocation to our leadership. The core objective of our project is to develop an analytical tool designed to enhance our understanding of the organization’s functioning, particularly in the realm of technology systems. The anticipated benefit is a more efficient and effective system, though quantifying this improvement remains elusive.
The composition of the team also poses its own set of challenges and opportunities. A larger team, while bringing more ideas to the table, inevitably leads to increased communication overhead. Additionally, involving less experienced members introduces a learning curve, which could decelerate progress due to the need for additional explanations, iterations, and the resolution of misunderstandings. However, this approach also has its merits, as it fosters knowledge sharing and skill development across the organization, enhancing overall competency.
Taking all these factors into account, we have decided on the following approach:
- Our initial phase will involve only engineers. We will engage with the Product team for feedback once we have a viable prototype.
- We aim to make this project a learning experience, hence we are open to participation from all interested individuals, regardless of their familiarity with Domain-Driven Design (DDD).
With these guidelines set, we called upon the Cartographers to embark on this journey.

The Plan
How do we collaboratively develop a Context Map that all contributors agree on? This aspect is seldom covered in standard DDD literature. Thus, our initial session was dedicated to establishing a clear workshop methodology.
Key questions we sought to address included:
- Scope: What boundaries are we working within?
• Answer: We are covering the bounded contexts of our system. We're not analyzing processes that are not yet covered with any code, nor parts that are outsourced to third-party solutions. - Focus: Are we examining our current operational state, or are we envisioning a future, ideal state?
• Answer: Our scope would center on identifying and understanding the current Bounded Contexts. A common pitfall, which was also luring us, is to try to fix the reality and create a Map of contexts that we would like to have, instead of mapping the existing landscape. - Workshop Structure: Is there an existing, effective workshop pattern we should follow?
• Answer: Lacking a predefined workshop template, we decided to adapt and improvise as we go. - Time Investment: How many sessions will this require, and what duration are we looking at for each?
• Answer: Our timeline was set at three months, with bi-weekly, one-hour sessions. - Sync/async: Will our efforts be solely synchronous, or will there be room for asynchronous contributions?
• Answer: With short time assigned to synchronous sessions, we complemented them with asynchronous tasks for participants. - Involving Product Team: At what stages should their input be integrated?
• Answer: We planned to engage Product Managers at two critical junctures: firstly, when the Bounded Contexts are delineated, and secondly, upon finalizing the Context Map.
Our plan was ready, we headed out to the execution.
Bounded Contexts
Imagine attempting to sketch a world map without any knowledge of continents. Similarly, crafting a Context Map is futile without understanding your Bounded Contexts.
The Candidates
Fortunately, our journey didn’t begin in uncharted territory. Over the years, we've hosted several Big Picture Event Storming sessions, encompassing either the entire organization or select segments. We also held smaller-scale workshops, ranging from Process-Level to Design-Level Event Storming. Additionally, we've maintained an up-to-date C4 model, which has proven invaluable.
Leveraging these historical artifacts, along with an intimate understanding of our codebase, we challenged our participants to identify potential Bounded Contexts, which we refer to as "Candidates" (some names were obfuscated).
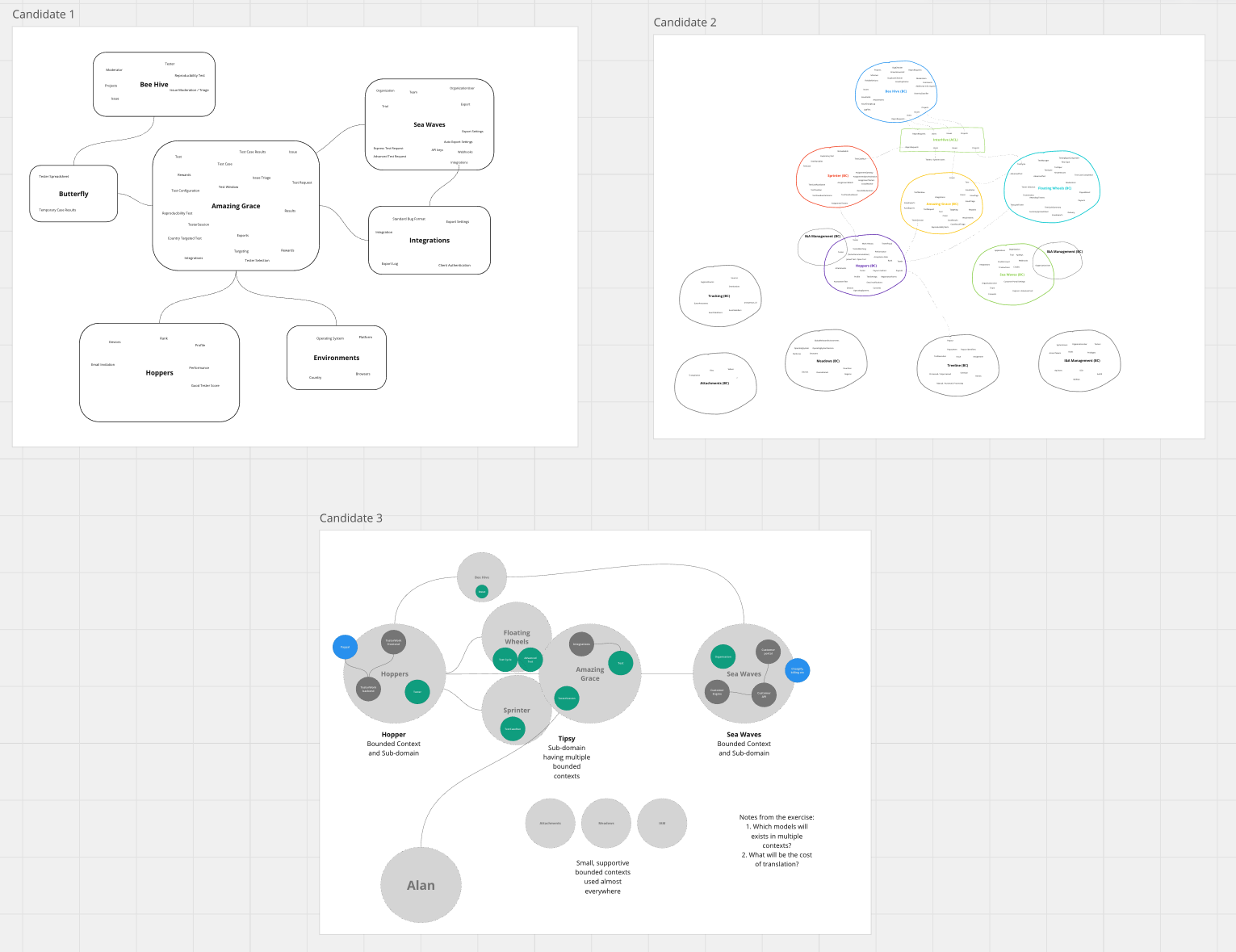
The visual representations above showcase three distinct interpretations of our Contexts, as proposed by different participants. The striking diversity in form highlights the lack of a uniform approach.
However, in examining the content, common threads and distinct variances emerged. But an intriguing question arose: does the recurrence of a Bounded Context across all proposals validate its existence? Certainly not. Such a consensus could merely reflect a shared bias, rather than objective truth.
This led us to the crucial phase of...
The Scrutiny
"Is what we're dealing with truly a Bounded Context?" This pivotal question became a recurring theme as we evaluated each candidate.
So, how do we determine if something qualifies as a "real" Bounded Context? This led us back to the fundamentals.
Let's first define a Bounded Context. At its core, it encapsulates the confines of our model, including its terminology, or what we call the Ubiquitous Language.
Our initial step should be an analysis of the language used:
- Identifying Homonyms: Are there terms used that sound alike but differ in meaning?
- Recognizing Synonyms: Do we encounter identical concepts described using varied terms?
Pinpointing these elements helps us differentiate between various Contexts.
Theoretically, this appears simple, but in practice, language can be complex and ambiguous, especially when domain experts hold varying viewpoints. Thus, we also explore additional heuristics, like organizational structure.
Which teams are involved in a specific context? It's plausible that implicit boundaries already exist, with different teams developing their models independently. The demarcation of their responsibilities could very well be the Contexts we're attempting to identify.
Yet, this approach has its limitations. What about smaller organizations where multiple teams share contexts? Or dynamic structures where code ownership has frequently changed recently? In such scenarios, relying solely on structural heuristics falls short.
Fortunately, there are additional heuristics at our disposal, including:
- Autonomy: Does the context operate independently in decision-making?
- Data Cohesion: Are there substantial data segments that often change or are used together, both in development and runtime?
- Single Source of Truth: Is there one definitive source for each piece of information?
- Cognitive Scope: Can the context's responsibilities be succinctly defined?
Remember, these are heuristics, not absolute rules. Domain Cartography isn't an exact science, akin to mathematics. Interestingly, neither is traditional cartography. Ever wondered how the border between Europe and Asia was determined? Or why Greenland isn't classified as a separate continent?
Subjectivity inevitably plays a role in interpreting these heuristics and reaching conclusions. Hence, collaborative effort is vital in this process - it's essential to find common ground in these interpretations to achieve results beneficial not just to the author.
So, we've meticulously scrutinized our Continents.
Here are our findings (again, with obfuscated names):
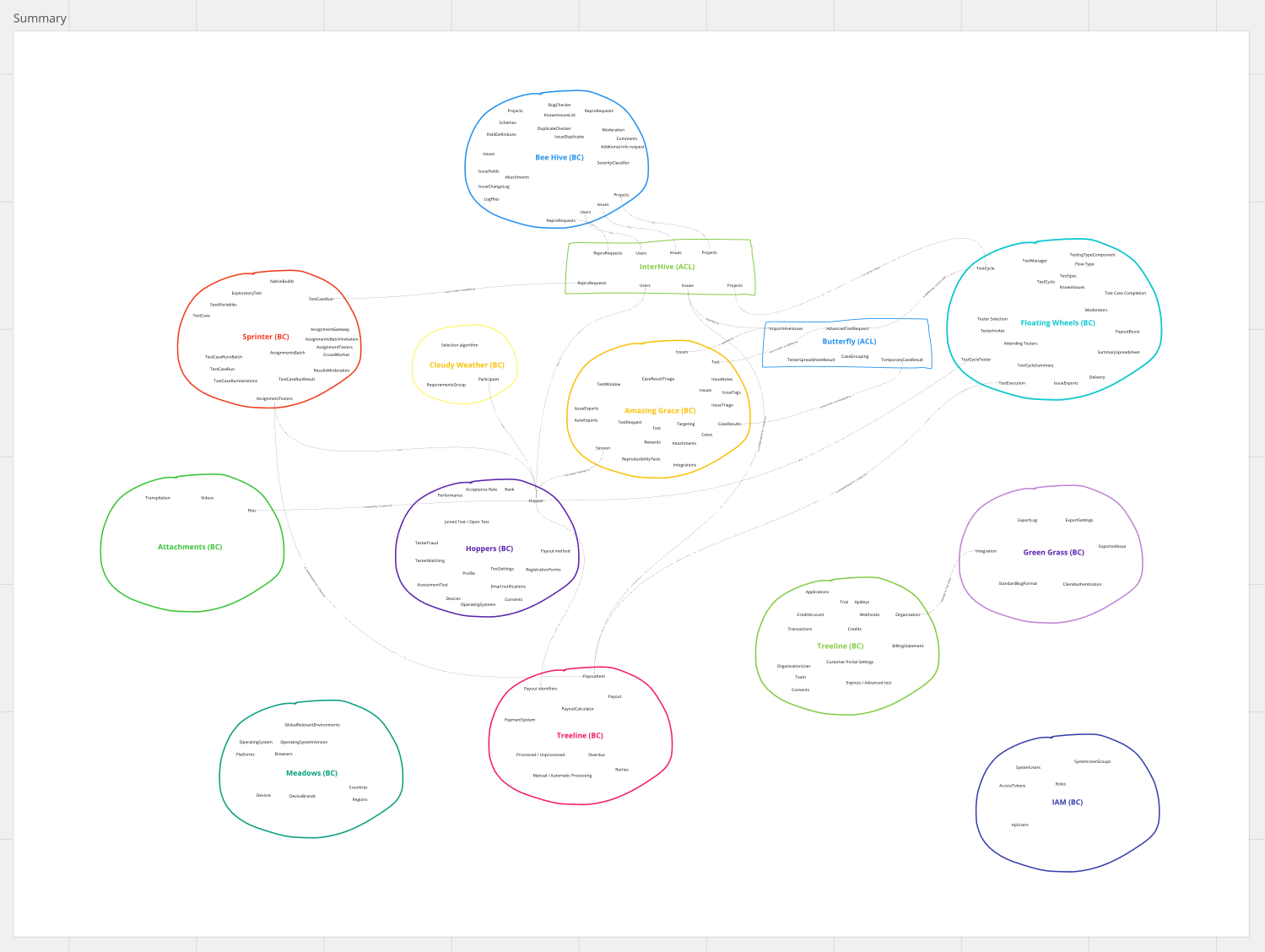
Context Map
If you look at the artifact above, in fact, it already looks like a map. There is a fancy colorful diagram with some terms floating around and some lines between them.
However, it's not what Evans and Vernon meant by the Context Map. Most of all, we haven't defined the relationships between the Contexts. The existing lines represent mere connections between terms across different contexts, but they fall short of defining the actual nature of these relationships.
To address this, our objectives are twofold:
- Uncover the true nature of the relationships between contexts.
- Effectively visualize these relationships for clarity.
Easy pease, right? Well, we've encountered two significant challenges:
- The sheer volume of relationships and perspectives involved.
- Deciphering the relationships as defined in the books.
The representation
In our quest for the ideal representation, we initially considered leveraging Context Mapper, a prominent tool in the domain. However, we encountered several limitations that led us to pivot toward a custom solution. One primary constraint was Context Mapper's reliance on Java, which diverges from our preferred programming language. Additionally, we sought a more intuitive and visually distinct way to delineate Contexts and their interrelationships.
Our team also recognized the need for a representation that could be comprehensible to individuals not deeply versed in DDD. This requirement further fueled our decision to develop a different approach, tailored to enhance clarity and accessibility for a broader audience. The details of our custom solution extend beyond the scope of this article, but you'll see a glimpse of it in the final result.
The amount
We've identified a total of 12 Bounded Contexts within the system. Each of these Contexts maintains some form of interaction with the others, ranging from closely intertwined to the "Separate Ways" relationship, which indicates no direct connection or dependency. This intricate web of interactions results in a total of 66 unique relationships, each representing a connection to be mapped. Imagine all those crossing lines on the diagram! And we should stop and think over each one of them to validate.
When you try to grasp it all at once, it's hard to put it into your brain RAM. So instead we've decided to focus on one Context at a time and create 12 maps instead of 1 to begin with. We divided the work among 3 participants who could work in parallel on that.
This was the result:

If you look closer, you can see that these variants differ:
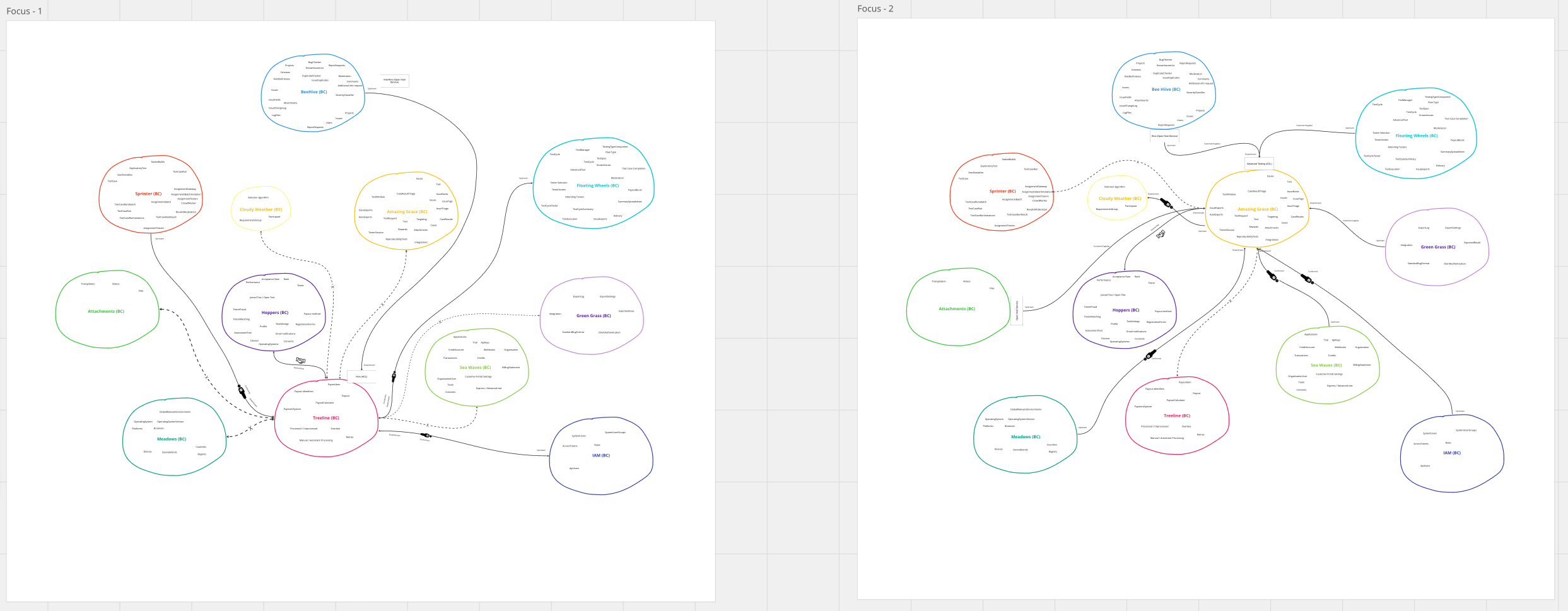
The next step was to integrate these 12 focused maps into a singular, comprehensive one.
Interestingly, the number of relationships effectively doubled to 132 in this unified map, because each relationship was examined from dual perspectives: one from the standpoint of the originating Context and the other from the receiving Context. This dual analysis served as a nice validation tool. Whenever discrepancies arose between the "from" and "to" perspectives of a relationship, it flagged potential conflicts, prompting discussions among the team members.
Relationships nature
At this point, in our discussions, it became clear that it was not always easy to grasp what is the essence of a given relationship.
It is often highlighted that relationships defined by Evans for the Context Maps are meant to describe how the Teams working on those Contexts are communicating with each other. But what if our organization structure is too small (few teams) or not stable enough and we cannot 100% tell that this Context belongs and belonged to a certain Team? Does it mean that it doesn't make sense to draw the Map?
But wait! Wasn't the definition of Bounded Context centered around the model and the language though? Can we look at the relationships from the model perspective? Eg. we can say that 2 Contexts are in Partnership relationship because they use concepts from each other in some way and whoever will work on those has to maintain close cooperation. Similarly, if there is a Conformist relation, it means that one Context depends on the other and accepts all the language from it without a translation layer.
This is the course we chose to take. The model-centric perspective allowed us to map relationships effectively, even when team-based associations were unclear.
The Artifact
In the end, we were able to merge the single-context-focused maps into one Master Map to Rule Them All. We looked at it and... decided that it was unreadable. We had to do some more iterations.
First of all, we've removed the Separate Ways relationships. In the end, if you're going Separate Ways, it's as if there were No Relationship.
Secondly, we've removed a few Contexts, because they were: a. separated by a well-designed Open Host Service, b. not stable, or c. not clear enough. This allowed us to go down to 9 Contexts instead of 12.
That's the result:
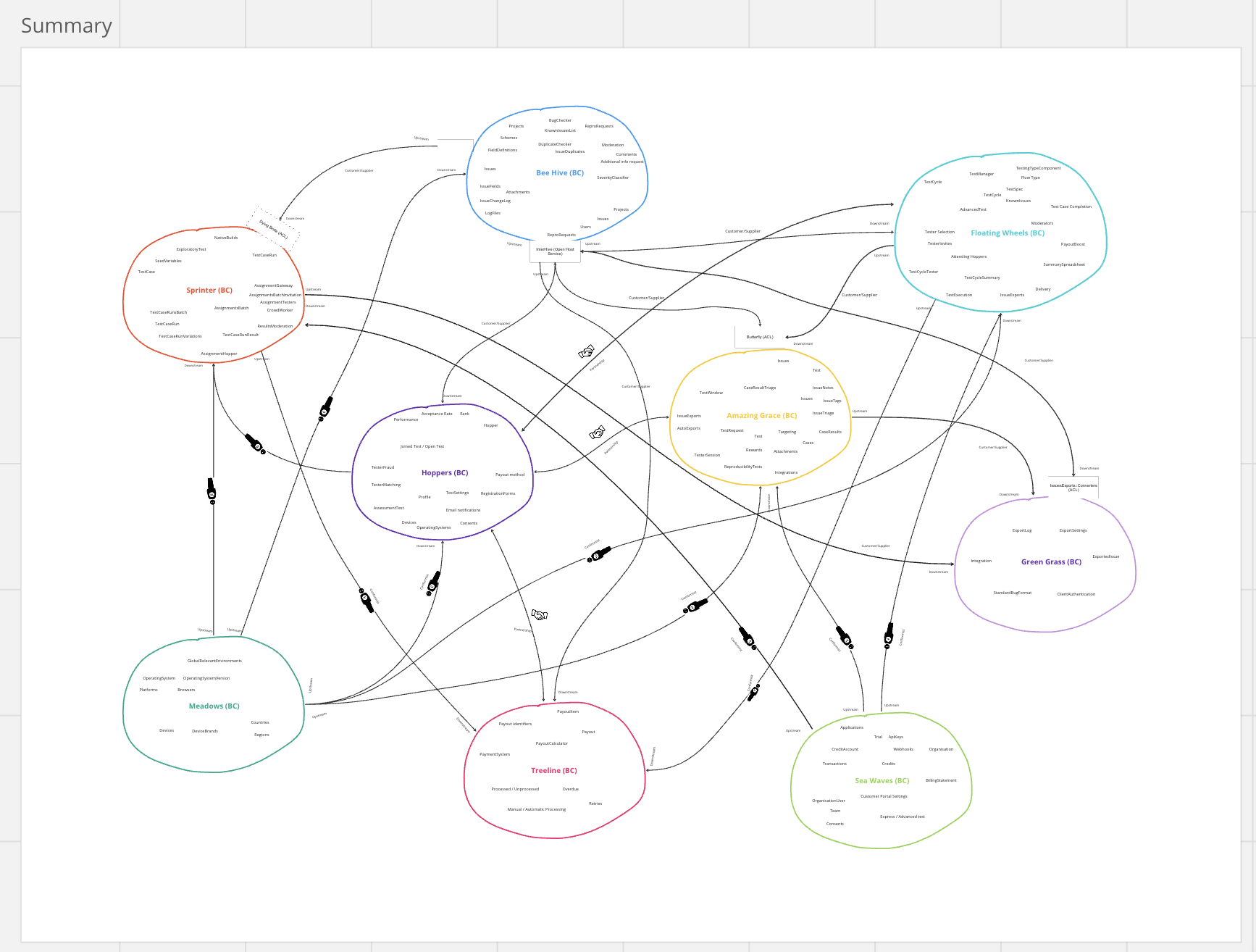
Ok, now it looked better, but we were still not fully satisfied because it was hard to draw some conclusions about our system based on it. It should be most of all useful to us, not only pretty, right?
Thus, one last step was to split the Master Map again into three smaller ones, which would show just one particular relationship - Partnership, Conformist, or Customer/Supplier. Thanks to that we could see clearly where we have dependencies between the Contexts and which Contexts require special communication between the owners.
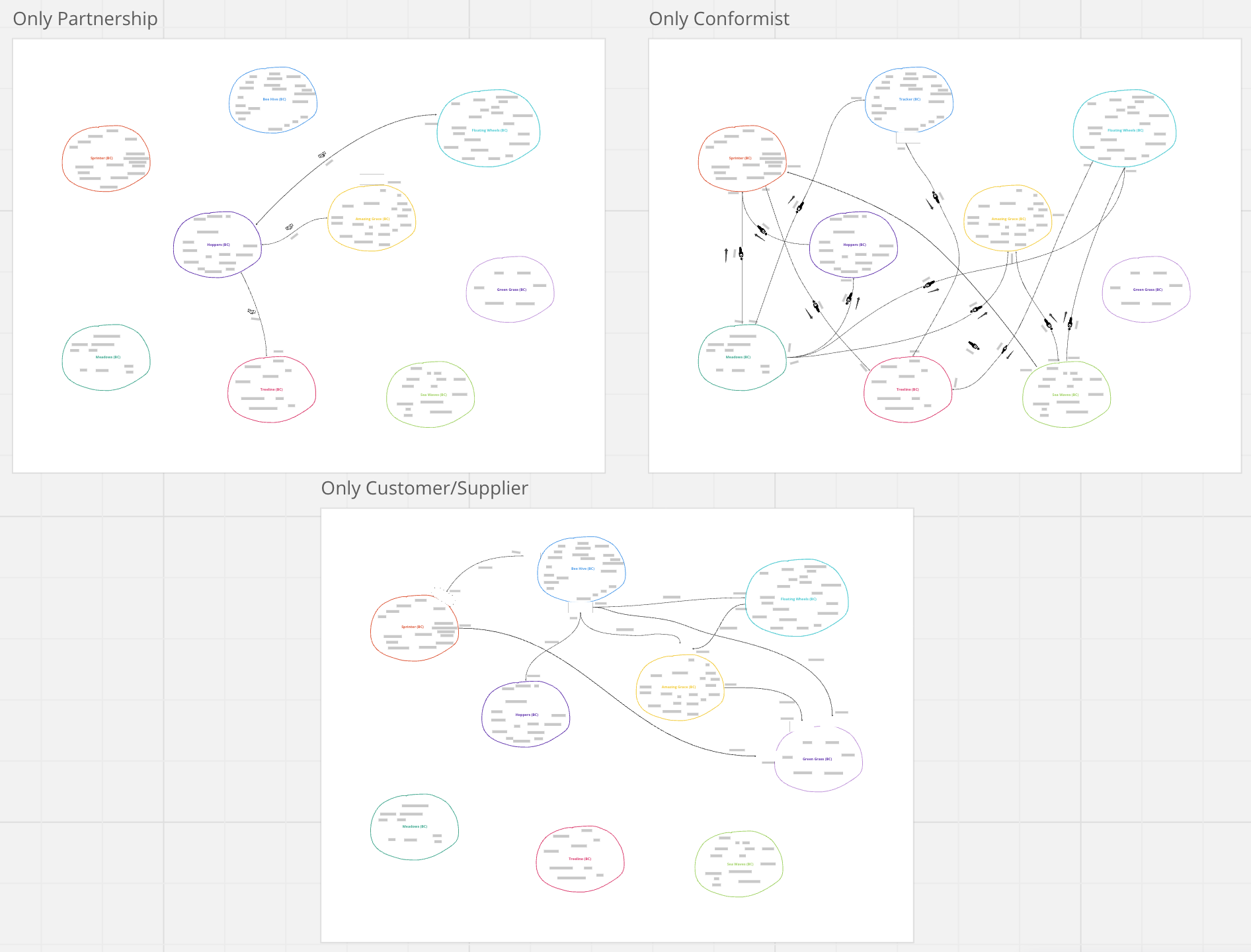
It took us a while, but finally, we had the Context Map that we wanted.
Conclusion
The process of drawing a Context Map isn't as easy as it might seem in the Blue Book and the Red Book. It requires defining the Bounded Contexts and then applying the ambiguous definitions for the relationships between them.
In the book the process is simplified, because the authors focus on a few Contexts at a time. It's completely understandable as their goal was to introduce concepts, not to show how it would look in a real-life scenario.
The question you might be asking at this point is - was it worth it? Is the Context Map useful to us?
In my team it is. It helps us plan the next Tech initiatives, to bring our system to the state in which Contexts are separated from each other in the code. More than once, it was used as a point of reference during code reviews, when we had doubts about where some concepts belonged. To me personally, it gave me an understanding of the system and a confidence to reason about it from the Domain model perspective.
