

It is the fundamental challenge in Artificial Intelligence, at least within the Reinforcement Learning framework, to learn to make decisions under uncertainty.
Thinking in terms of the primary components of a Reinforcement Learning model, where an Agent interacts with an Environment performing certain Actions to obtain a Reward, as shown below:
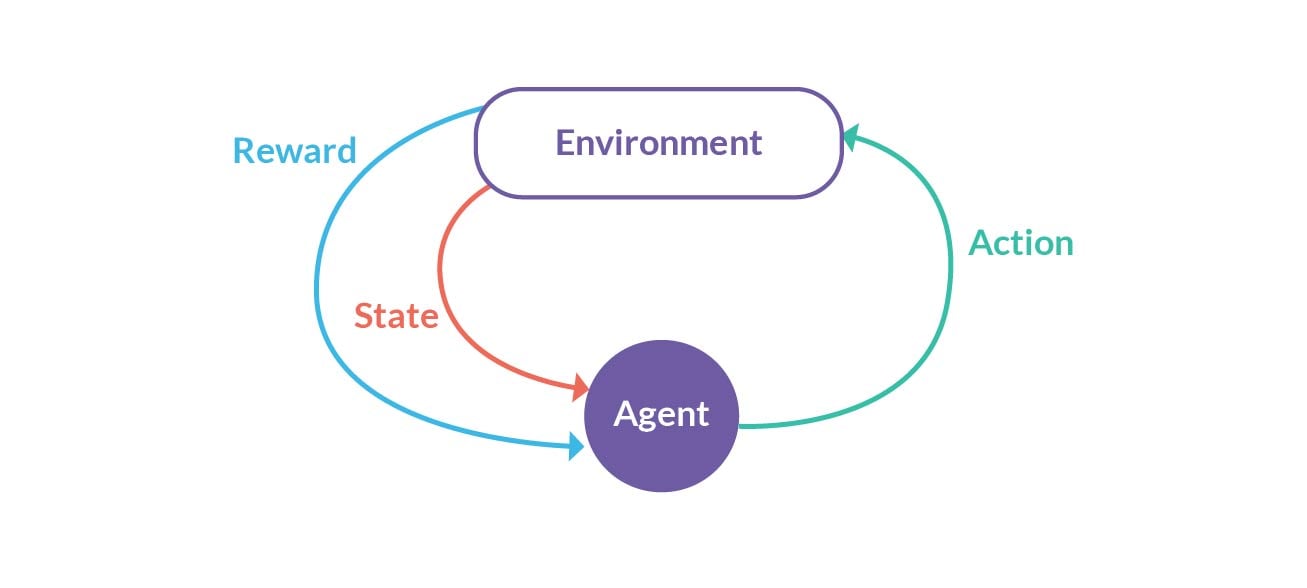
To do so, we need to develop intelligent agents and teach them to take actions in an environment so that they can maximise the cumulative reward.
The goal here is as noble as it is uncomfortably complex. These complexities quickly become strong taunting sources in many respects, including the versioning and tracking developmental progression of a project.
In this post I will try to unveil a little mystery on how we at GAT tackle the issues of versioning the code, static and dynamic data, models and Environment - the key elements of an RL research endeavour.
Background
Version Control Systems (VCS) have been at the forefront of sanity for most coders ever since the early occurrences of software-developmental creative destruction.
Code versioning systems have come to save the day of software development projects in so many cases and manners that even a swift mathematician would have to rack their brain to try and calculate - and chances are they would still fail.
With the advent of Machine Learning and Artificial Intelligence as a primarily IT domain (at least from the technical standpoint), resulting from almost chef-level concoction of copious amounts of data accumulated by companies and the compute power available to process them, the need to systematically preprocess, analyse and model these data feels only natural and congruent with both the academic and business needs of institutions across the globe.
Data Scientists version more. We do not only version code. We want to version our data and their preprocessing steps, our experiments, our models and their parametres, and in the case of Reinforcement Learning (RL), our environments. This kind of logging used to be done in the past in Excel spreadsheets (or a similarly painstaking tool) for lack of a better option, and, perhaps unsurprisingly, this inconvenient, error-prone, slow and detached process did not stand the test of time (phew!).
Experiment tracking has since come a long way, and we have and still are witnessing an upsurge in tools and frameworks that provide experiment tracking functionalities (check out Weights and Biases, MLFlow or Neptune to name just a few). These tools usually offer an API you can call directly from your code to log the experiment information. They also usually come with dashboards to visualise and share the results.
These features notwithstanding, Reinforcement Learning still remains a supervenient domain in terms of being a "target group" for experiment versioning, which directly results in a need to find circumventive ways to fully implement the Experiment-as-Code approach.
The Research Process
At the process level, the design does not introduce any peculiarities that stand outside the definition of a good old-fashioned scientific method. What we have done is to map its elements against the tooling used within the project. With this in mind, every research element comprises a research question posed, which we attempt to answer through a set of hypotheses tested via experiments.
The mapping between concepts and tooling is captured in the table below: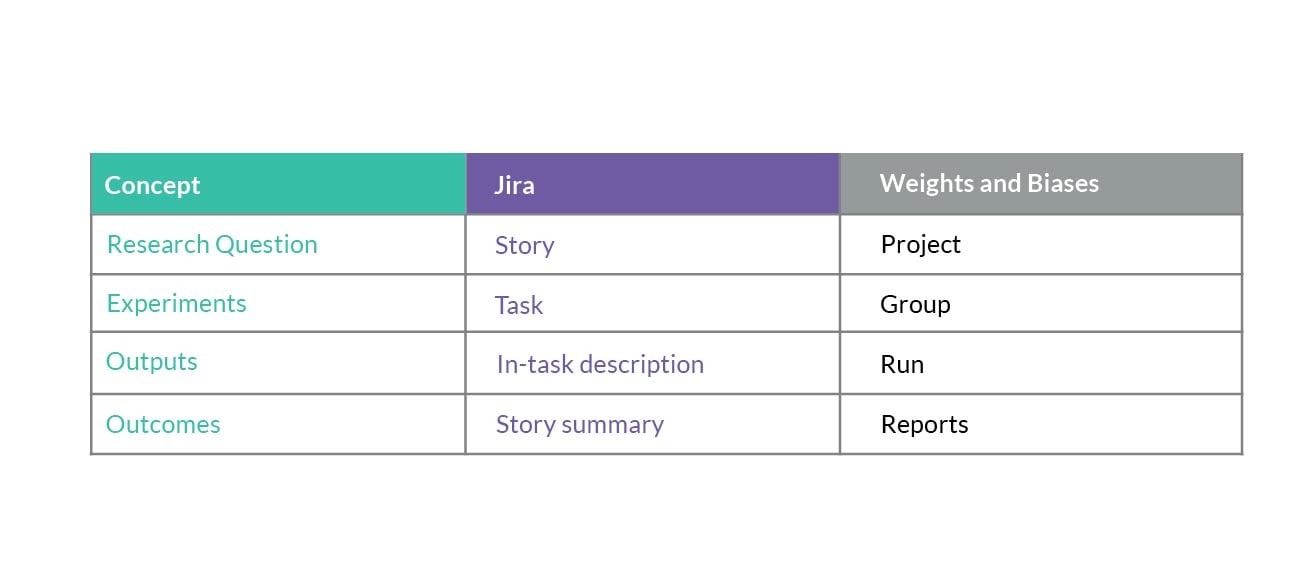 where:
where:
- Research question defines the scope of an endeavour, and includes the definition of a problem as well as the experimentation scope - the set of experiments envisaged to be conducted,
- Experiment includes its scope, expected outputs and a conclusion on a particular hypothesis,
- Outputs comprise raw information about the experiment results, changes in (hyper)parameters of an experiment and results of any changes made as compared to the previous iterations,
- Outcomes provide a more discussion-like analysis and interpretation of the result of a series of experiments, pinpoints the impact of a research question and its artefacts, as well as any other residual information.
As a side note, the choice of the tools in our example is not accidental - we currently use these in our experiment versioning and tracking processes, since we have found they map to our needs the closest.
Data Versioning
The notion of data is not an obvious or direct one in RL (and if not in RL in general, definitely in our project), insofar as one does not have the perceived luxury of dealing with static data. This luxury is typically reserved for academic contexts, where well defined environments are a must for benchmarking purposes. For business applications the need to engineer your environment on your own, hence it quickly becomes an iterative process. One (of many) ways to at least partially circumvent that hindrance is to handle input data through the notion of representation.
David Marr's Vision: a Computational Investigation summarises this concept as a formal system which "makes explicit certain entities and types of information", one that can be operated on by an algorithm in order to achieve some information processing goal (in our case, translating a web application's structure into feature encodings). With that done, such a representation is passed to our interface (or Environment) to be explored and tested by our Agent. Bearing in mind the fact that representation learning also requires model training and evaluation, it is up to this point that the project lends itself to the straightforward experiment versioning pipelines quite seamlessly. From then on, however, it is the RL algorithmic machinery that takes over, generating artefacts and data on-the-fly, which equally as seamlessly makes the tracking element problematic. Thus, the search continues.
RL Models and their versions
Referring back to the RL model figure at the start of the entry, let us ponder the functional implications and their taxonomy to shed more light on their properties, through the lens of trackability.
The properties of interest include:
- Optimisation (whose goal is to find an optimal way to make decisions, i.e.
one that yields the best possible outcomes in a particular scenario - please forgive the gross simplification). - Delayed Consequences (consisting in realising that some decisions made now can have an impact on things much later in time)
- Exploration (learning about the world by making decisions. The obstacle
here is that one can only get a reward for a decision made) - Generalisation (understood as reasoning from detailed facts to general principles)
In order to successfully train an Agent under such conditions, it follows that:
- A model may have different trained weights or hyperparameters, for a different environment (it may optimise differently), which in turn may lead to...
- ... an Agent behaving differently on different Environments (due to
Exploration), thus rendering the element of Generalisation more difficult to tame, and thus... - …make the Delayed Consequences that much harder to estimate (as if the Temporal Credit Assignment was not hard enough).
Considering the above, the natural question arises: How to go about tackling this challenge? The answer lies (again, only partially) in some of the experiment tracking tools such as Weights and Biases or comet that allow us to track separate code branches that link to corresponding training sessions, but that is about it. Still no cigar, but we are getting there!
One tool to glue them all
To call docker a version control system would be an exercise of farfetchedness. Its typical use case is as a deploy artefact only. However, we have found that as a stand-alone, executable package that consists of code, runtime, system tools, system libraries and settings, it answers most of our needs in terms of both training and evaluation (aka inference). While not without its limitations (finite number of write layers, tracking the entire chroot, binaries etc.), docker has all the features and capabilities we have otherwise been missing. Owing to the aforementioned changes in RL model (hyper)parameters for a given environment, we need to be able to create an Environment setup in its entirety - code + model checkpoint, which docker allows us to do exactly as we require. On top of that, docker is an inherent part of the CI/CD pipeline which in turn renders it extremely practical to wrap each training branch or commit with extra dependencies/artefacts almost at no cost.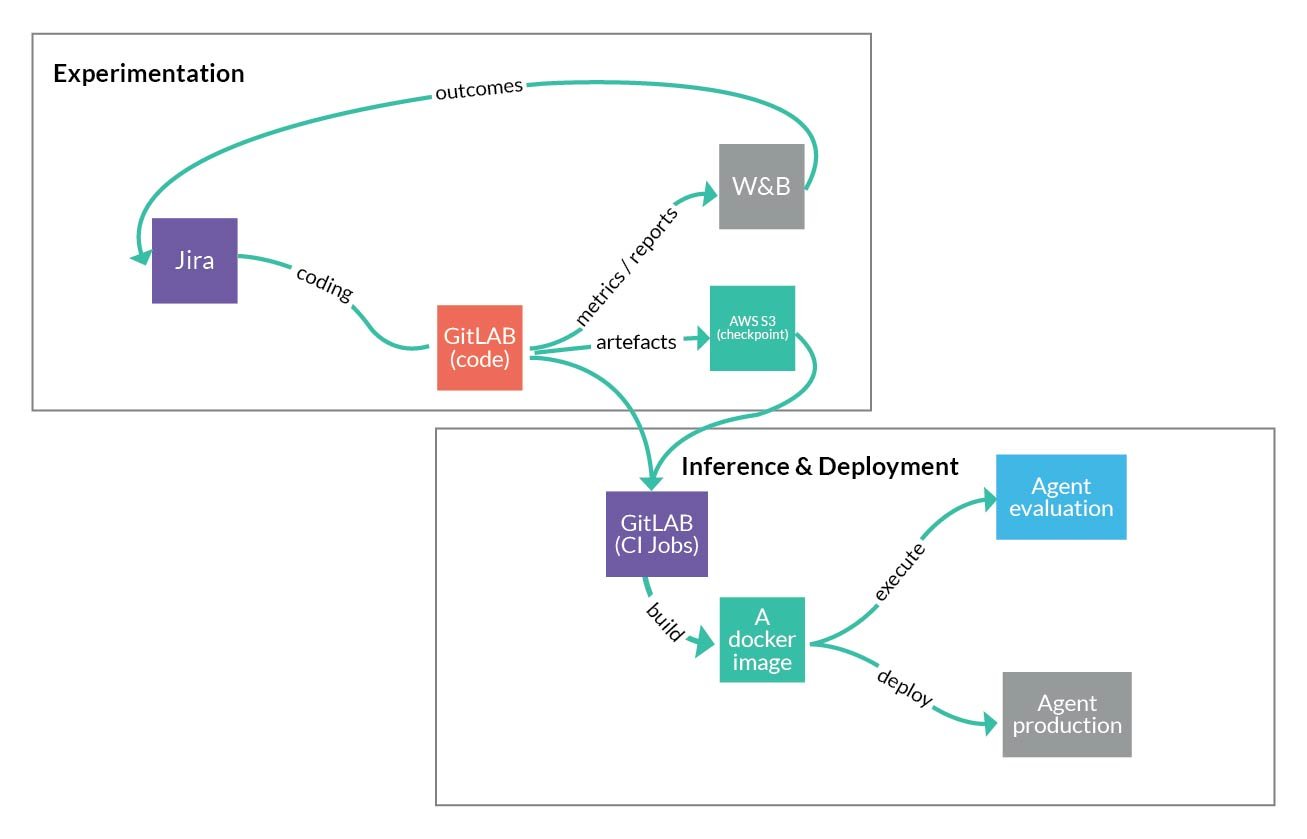
Conclusion
To quote my colleague, "practical Reinforcement Learning is hard!". The subject matter itself aside, there are also many other practical considerations to be taken heed of during the experimentation, training, inference and deployment stages. We have looked at some of the API-based experiment versioning systems, the ways they can be contributory but also hindering in the context of the said "practical RL". We have also included docker as a quasi versioning tool to aid with the stability and replicability of experiments to as high degree as possible.
I sincerely hope I have achieved my goal in unveiling at least some mystery in terms of how to approach the Experiment-as-Code concept from start to finish. I am curious to learn about how your twists and turns unfold when it comes to experiment versioning.